Small Model, Giant Intellect: How China’s VibeThinker-3B is Defying LLM Scaling Laws
The prevailing wisdom in Artificial Intelligence has long been that bigger equals better. For years, the industry has pushed toward massive, trillion-parameter frontier models to achieve breakthroughs in reasoning, mathematics, and complex coding. However, a massive shift is occurring as highly optimized, smaller architectures begin to punch far above their weight.
Enter VibeThinker-3B.
Developed by WeiboAI—the AI division of Weibo, often referred to as the Twitter of China—this open-source model is only 3 billion parameters. Yet, it is going toe-to-toe with models hundreds of times its size, proving that extreme efficiency and advanced post-training can replicate the capabilities of tech giants right on your local hardware.
Watch the Technical Breakdown
Before we dissect the benchmark performance, watch this breakdown of how this small model is reshaping open-source development standards:

Shaking Up the Global Leaderboards
The true shockwave of VibeThinker-3B comes from its reasoning data. WeiboAI utilized a Systematic Optimizing Principle (SSP) post-training pipeline, focusing heavily on challenging STEM fields, competitive programming, and complex mathematics.
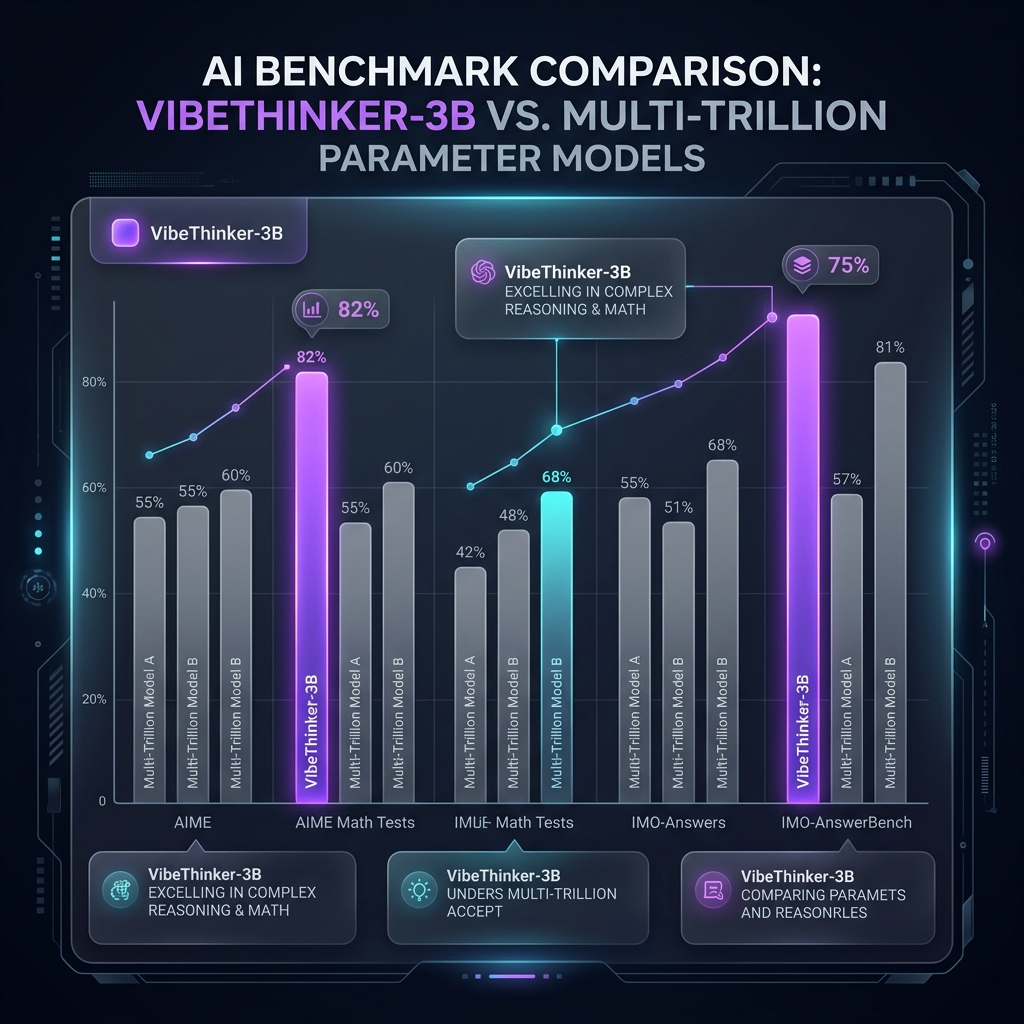
When tested against massive industry benchmarks and competitive architectures, the 3B model holds its own against top-tier reasoning models like Gemini 3 Pro, Qwen 3.6 Plus, GLM, and Kimi. Its capabilities shine in specialized testing environments:
- Olympiad-Level Mathematics: High scores across strict math evaluation suites like AIME '25, AIME '26, HMMT '25, and IMO-AnswerBench.
- The LeetCode Performance: In recent LeetCode weekly and biweekly programming contests, VibeThinker-3B successfully passed 123 out of 128 problems on its very first attempt—achieving an astonishing 96.1% acceptance rate.
Note on Architecture Limitations: While highly capable at reasoning, the developers note that VibeThinker-3B was explicitly not trained for tool-calling, agent orchestration, or autonomous coding agents. It is designed purely as an elite math and logic reasoning engine.
Why 3 Billion Parameters Matters
An elite 3B parameter model is a massive win for localized computing. Up until now, achieving high-end logic and competitive programming intelligence meant paying premium monthly subscriptions for cloud-hosted APIs.
With a 3B footprint, this level of cognitive power can easily run locally on a standard consumer laptop.

By using localized test-time scaling strategies like CLR boost, developers can run deeply thorough, multi-step verification prompts locally, keeping their data completely private and eliminating expensive external cloud infrastructure costs.
Key Takeaways: The Efficiency Revolution
| Feature Metrics | Traditional Trillion-Parameter Models | VibeThinker-3B Framework |
|---|---|---|
| Compute & Hardware | Server farms, massive cloud clusters, high VRAM requirements | Local execution; easily handled by modern consumer laptops |
| LeetCode First-Try Rate | High operational costs to maintain elite coding accuracy | 96.1% acceptance rate (123/128 problems passed first-try) |
| Availability | Gated behind corporate API paywalls & usage tiers | Free and Open-Source weights available on Hugging Face |
- Democratic Coding Power: The tier of advanced reasoning that developers used to pay premium monthly fees to access is now a free utility.
- Localized Math & Logic: High-end STEM performance can be embedded natively into local software environments without relying on third-party uptime.
- The Power of SSP: WeiboAI's post-training methods demonstrate that data optimization and training philosophy matter just as much as raw parameter scale.
Conclusion: The Rise of Bespoke Local Engines
The launch of VibeThinker-3B proves that the race for massive scale is no longer the only path forward in AI development. By optimizing smaller architectures for extreme logical precision, developers are gaining access to highly efficient tools that don't compromise on industry credibility.
Whether you are looking to run advanced local code validation or deploy local mathematical verification pipelines, the weights are open, free, and ready to test.
Download the Full Technical Guide
Access the deep-dive PDF analysis detailing the Systematic Optimizing Principle (SSP) post-training process, Olympiad benchmarks, and Contests performance datasets.
Download PDF Guide
