
Day 2: Data Wrangling Architecture — Mastering the Core Mechanics of Pandas
Yesterday, we established a professional development workspace, focusing on environment isolation and structural execution rules. Today, we are moving directly into the structural core of Phase 1 (Week 1–2): Python + Data. As an AI engineer, you will quickly realize that raw computational power means nothing if your underlying data ingestion layers are fragile or malformed.
Before an LLM can parse a context window, or before a retrieval-augmented generation (RAG) system can chunk documents into an indexing database, the data must be systematically parsed, transformed, and structured. In Python, the industrial standard tool for this task is Pandas. Today, we transition from viewing tables as plain spreadsheets to managing them as programmable high-speed matrices.
The Core Foundations of Tabular Arrays
To write fast, optimization-focused data transformations, you must understand the two core architectural structures that Pandas uses to organize memory:
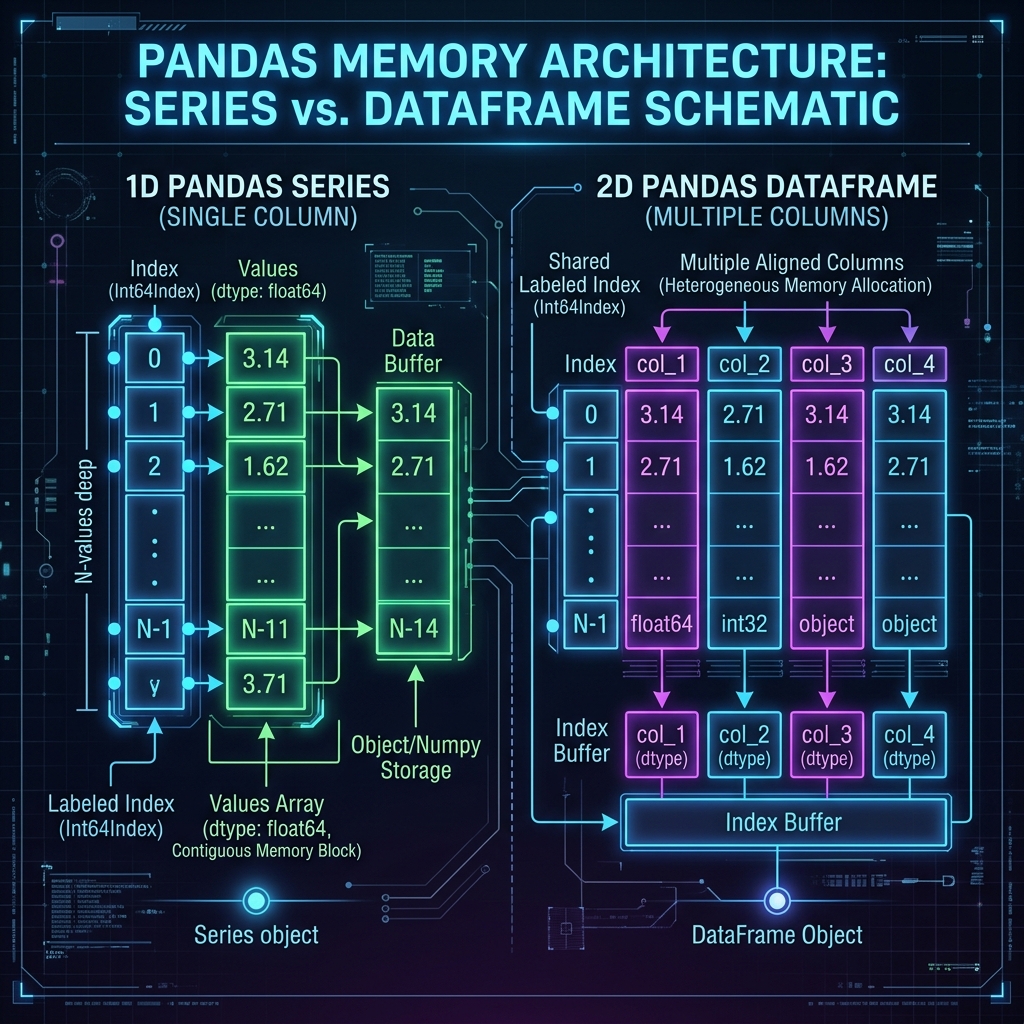
- The Series: A one-dimensional, labeled array capable of holding any data type uniformly. Think of it as a single data column bound to an immutable index sequence.
- The DataFrame: A two-dimensional, size-mutable tabular data structure with labeled axes (rows and columns). It acts as a collection of aligned Series objects sharing a common index mapping.
Essential Methods for Quick Data Ingestion
When your data ingestion pipeline receives a brand-new raw file matrix, your code must perform a structural triage before attempting extraction routines. Avoid printing out entire raw files to terminal windows; instead, use these native alignment operations to map your data:
df.head(n): Inspects the top $n$ records to evaluate raw ingestion formatting.df.info(): Maps full architectural dtypes, column memory signatures, and missing null constraints.df.describe(): Generates mathematical summary vectors (mean, standard deviation, percentiles) over numeric records.
Structural Data Manipulation and Cleaning
In production environments, datasets are inherently messy. They arrive filled with text formatting discrepancies, missing parameters, and trailing spaces that degrade token parsing efficiency inside LLM layers. Clean data orchestration relies on three main execution pillars:
1. Advanced Slicing and Filtering
To optimize memory performance, you should avoid slow Python loops and instead use optimized indexing filters like .loc[] (label-based slicing) and .iloc[] (integer-based position slicing).
2. Eliminating Null Traps
Unchecked missing data will cause downstream machine learning layers to throw segmentation faults. Your pipeline must enforce strict resolution rules: dropping critical data failures using .dropna() or programmatically substituting empty cells with baseline vectors using .fillna().
3. Split-Apply-Combine Operations (groupby)
To calculate high-level data summaries across major categories, use the .groupby() pipeline pattern. This operation splits your tabular data into independent sub-segments, applies mathematical aggregations (such as sums, counts, or averages), and combines the final results into a clean summary table.
Core Task: Ingest, Process, and Export
To pass Day 2, you will write an automated ETL (Extract, Transform, Load) data processing script inside your local workspace.
Create a Python script utilizing Pandas that executes the following functional operations:
- Programmatically load a messy CSV file containing mock transaction metadata.
- Identify and drop rows where critical identification keys are completely missing.
- Normalize all column header naming formats to strict snake_case conventions.
- Aggregate total processing volume grouped by regional sectors.
- Export the clean structured result into an optimized localized file system.
Key Takeaways for Day 2
| Operation Target | Engineering Implementation | The Production Anti-Pattern |
|---|---|---|
| Data Ingestion | Run df.info() to verify column memory types |
Printing entire high-volume arrays directly to standard output |
| Data Cleaning | Handle null rows gracefully using .fillna(0) or explicit drop criteria |
Allowing raw null strings to pass directly into machine learning models |
| Aggregation | Use vectorized .groupby() methods for massive scale changes |
Writing slow, sequential nested loops to calculate categorical sums |
- Vectorization Over Loops: Pandas operates on optimized underlying C-libraries. Vectorized actions run exponentially faster than writing custom Python loops to parse rows.
- Data Integrity Matters First: If your data filtering step allows corrupted text strings or formatting anomalies to remain, your vector embeddings will contain semantic noise.
- Document Your State Changes: Keep a clean log of your DataFrame's shape updates across every transformation milestone to catch structural drops instantly.
Conclusion: Building Clean Data Pipelines
Mastering Pandas transitions your workflow away from basic file viewing toward building automated data pipelines. By enforcing strict data cleaning constraints, configuring structural groupings, and ensuring type consistency, you build the secure data foundations required to feed structured tables into predictive modeling networks and agentic context arrays.

